背景
WPAI深度学习平台是集开发实验、模型训练和在线预测为一体的一站式算法研发平台,旨在为集团各业务部门赋能AI算法研发能力,支撑了58同城搜索、推荐、图像、NLP、语音、风控等AI应用。
WPAI平台上包括离线模型训练作业和在线模型推理服务两大类任务,在旧有部署模式下,模型训练作业和推理服务是两套资源完全隔离,而在线模型推理服务具有明显的潮汐特性,白天为流量高峰资源使用率高,夜间为流量波谷,资源使用率低,如何将夜间波谷空闲资源进行充分利用提升平台资源利用率成为WPAI需要解决的问题。本文介绍如何通过离线训练作业和在线推理服务的混合部署,将在线推理服务夜间波谷空闲资源出让给离线模型训练作业使用,并重点阐述混合部署中涉及到的资源调度难点。
为降本提效,WPAI已经上线了在线推理服务的自动弹性扩缩容,在此基础上之,我们又上线了离线训练作业和在线推理服务的混合部署,当在线推理服务处于波谷时,在线出让资源给离线任务使用,充分利用在线业务的空闲资源。
混部前提:自动弹性伸缩
WPAI深度学习平台构建了一套自动弹性扩缩容系统,可以提供以下能力:
- 智能扩容能力:模型推理服务的扩容需要开发人员主动触发,当流量暴增时,业务有损时间取决于开发人员对报警的响应速度,智能扩容能力可根据模型推理节点资源使用情况自动调整节点数量,流量突增时无需人工干预。
- 自动缩容能力:(1)业务倾向于申请比实际需求更多的资源以确保服务的稳定性,通过自动缩容可回收服务申请的冗余资源,提升平台GPU使用率。(2)推理服务具有明显潮汐特征,白天流量高峰资源使用率高而夜间流量低资源利用率低下,通过自动缩容能回收波谷资源,将波谷资源出让给模型离线训练使用,进一步提升平台的GPU利用率。
线推理服务和离线训练作业特点
首先我们对比一下离线训练作业在线推理服务的不同。离线训练作业像是吸水的海绵,其业务体量大,对于GPU和CPU计算能力,有多少就能用多少,而在线推理服务会需要更高的响应时间,用户倾向于申请⽐实际需求更多的资源以确保服务的稳定性,且在线推理服务具有典型的潮汐性,如下图所示。
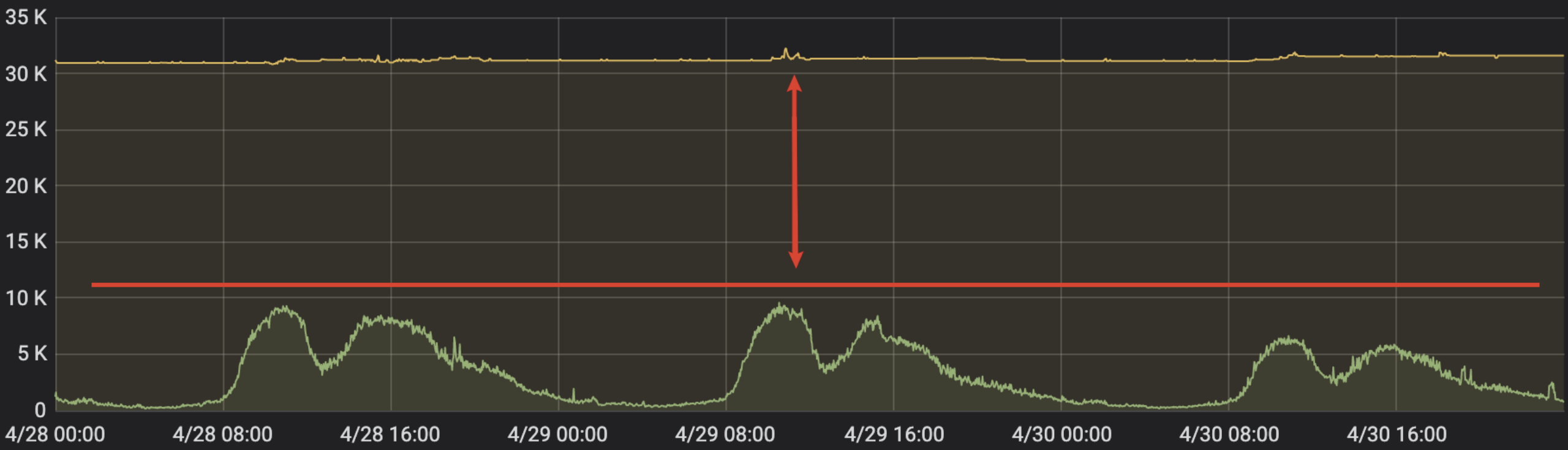
总结一下在线推理服务和离线训练作业区别:
| 在线服务 | 离线作业 | |
|---|---|---|
| 时延 | 敏感 | 不敏感 |
| SLO | 高 | 低 |
| 负载模型 | 白天负载高,夜间负载低 | 只要运行,负载就很高 |
| 错误容忍 | 错误容忍度低,高可用 | 允许失败重试 |
通过在线推理服务的弹性伸缩能回收波谷资源,而回收的波谷资源如何加以利用让离线作业使用呢?混合部署可以解决这个问题。
混合部署是将在线推理服务或离线训练作业部署在同一集群或同一服务器上,那么如何通过混部控制实现在离线之间资源的灵活拆借,对此我们调研了目前成熟的混部方案,可以总结为以及下2种:
-
方案一:在线服务和离线作业部署在同一台服务器上,该方案需要对Linux内核做改造:离线作业一般都是CPU/GPU密集型任务,出现资源抢占时会影响在线服务的稳定。为了确保在线任务稳定性,需要对网络资源、磁盘以及内存带宽、L3 Cache等做隔离,以满足在线服务需要资源时能及时抢占,离线作业能快速让出资源。
-
方案二:在线服务和离线作业部署在同一集群,可以通过整机出让的形式,将整台在线服务器出让给离线作业,同时需要做好离线作业重调度。
离在线混部架构设计
基于前面背景及技术方案调研分析,提出了如下设计目标:
- 在线服务SLO受保证,离线训练作业不能无限填充
- 在线服务需要更多资源时,离线训练作业能及时避让
- 离线训练作业的成功率受保证,不能因为频繁受限,导致失败率很高
同时,因为方案一部署在同一台服务器需要对内核做深度定制,因此采用方案二:在线服务和离线作业部署在同一集群。
接下来,先介绍混部核心设计资源池划分及出让、节点状态,然后介绍整体架构设计,最后重点介绍模块关键实现。
资源池划分
为防止离在线服务部署在同一服务器上对在线推理服务的影响,采用在线推理服务和离线作业不熟在同一集群的方案,因此,首先对集群进行了划分。
将所有服务器通过k8s labels分为在线、混部、离线三个资源池
- 在线:只跑在线推理服务
- 离线:只跑离线训练作业
- 混部:白天跑在线推理任务,晚上跑离线训练作业
同时调度规则如下:
- 在线推理服务自动扩容pod 优先调度到混部
- 在线推理服务自动缩容优先销毁混部
- 夜间短时离线训练作业优先调度混部
即采用两阶段混部模式,错峰实现资源动态配比
⽩天:离线出让定量资源填补在线⾼峰资源缺⼝
夜间:弹性伸缩出让闲置资源⽀持离线训练
基于在线资源使用率资源出让
监控在线集群资源使用率,将弹性资源折合成同等规模的机器,如下图所示。
- 初始时集群满载,配置集群资源使用率阈值 y
- 在线服务整体缩容,集群部署⽔位下降⾄ x
- 感知 y > x,选择节点进⾏实例驱逐,腾出整机出让给离线
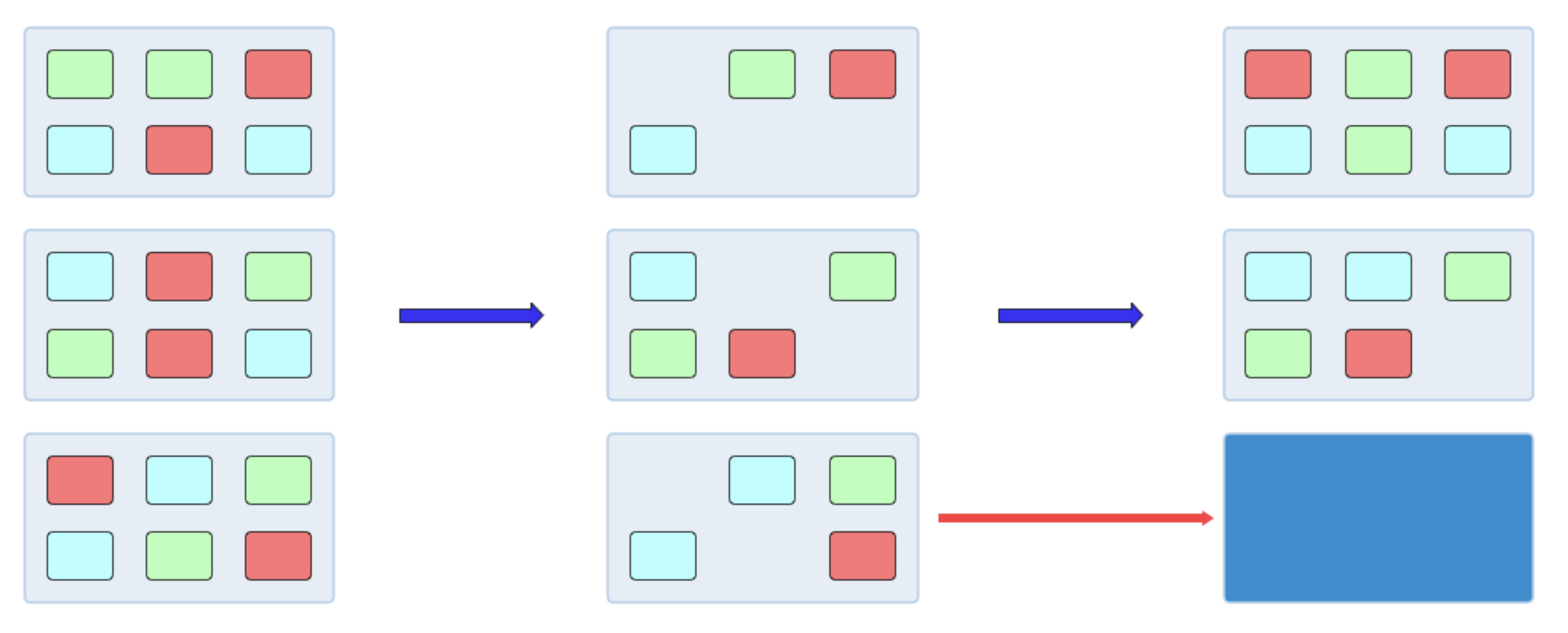
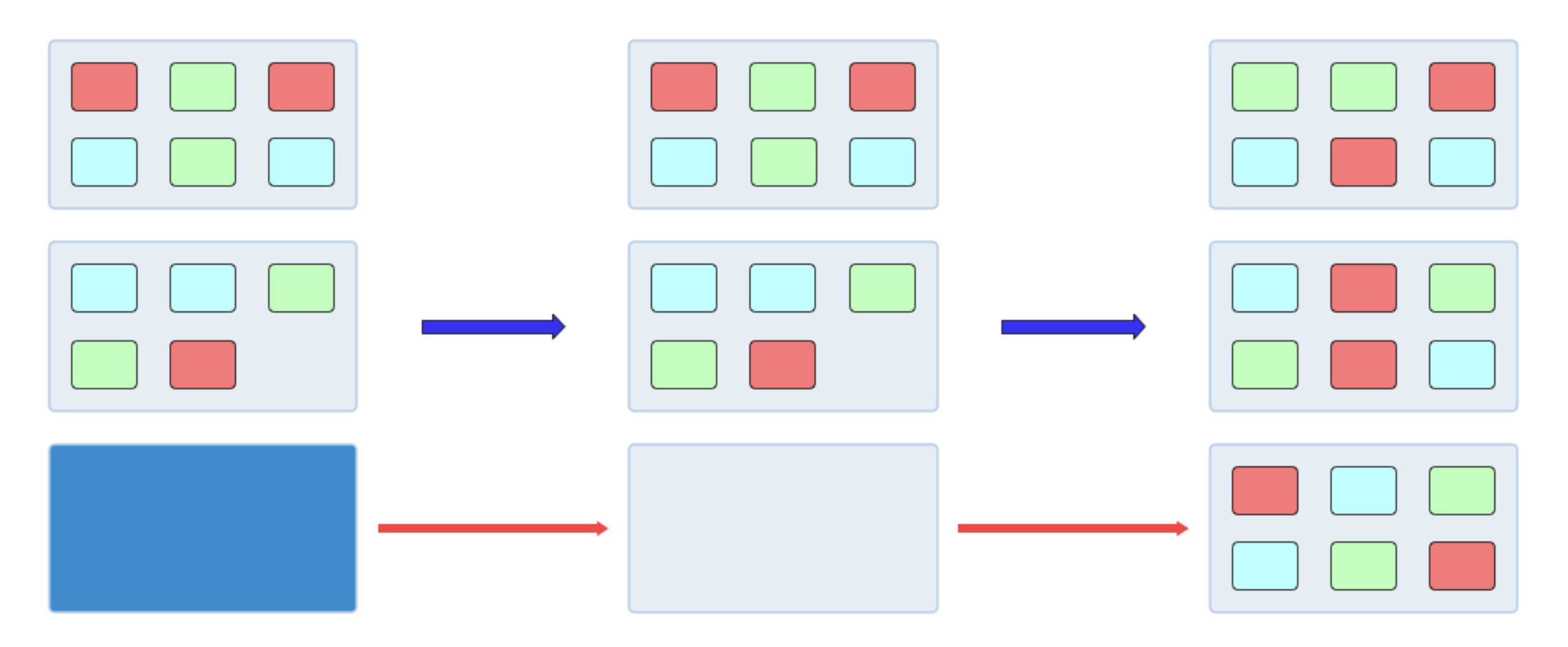
当在线任务需要资源使用率上升,离线训练作业被驱逐,归还给在线推理服务。
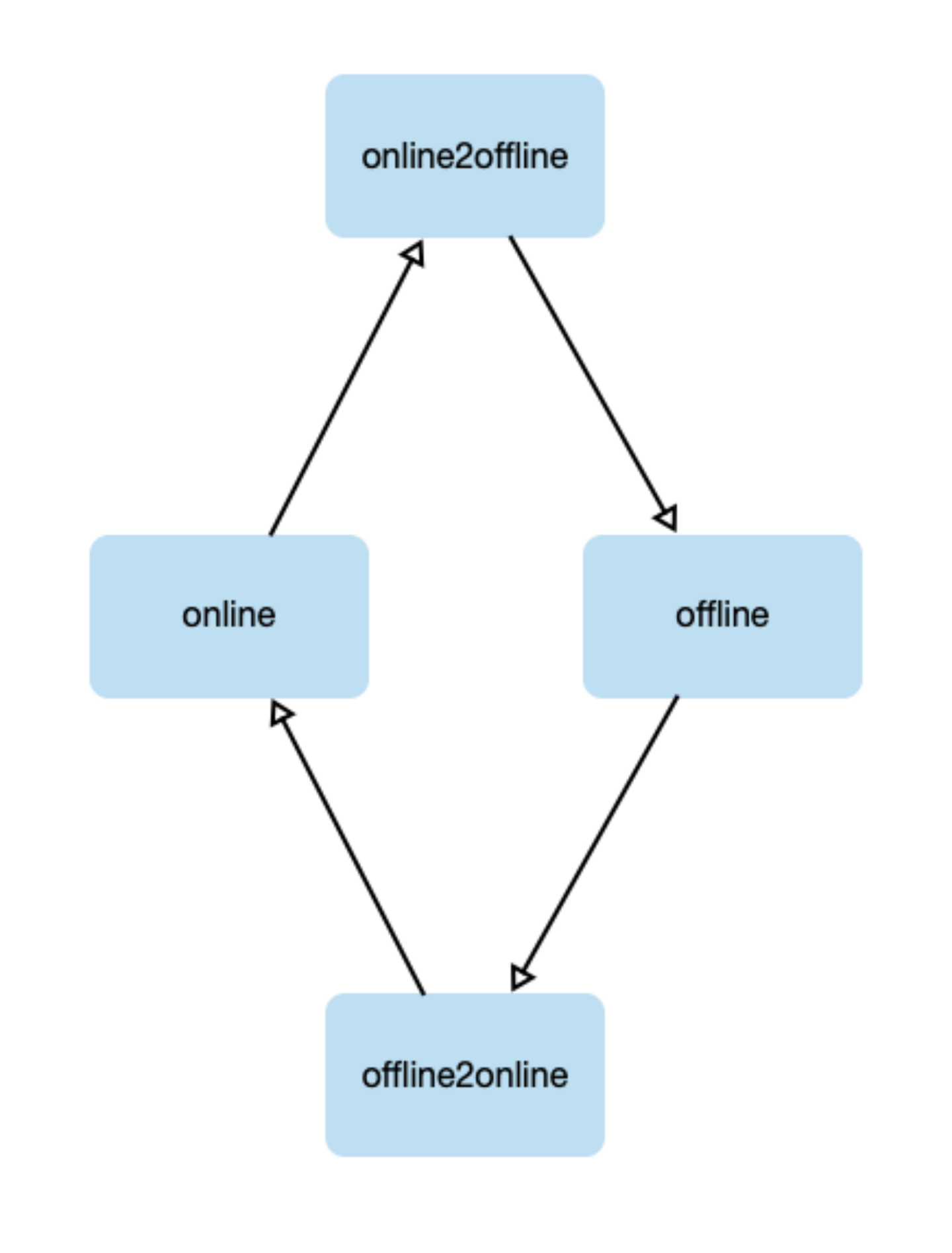
节点状态变更
节点由离线转为在线或在线转为离线时,需要将原Pod驱逐,Pod会执行优雅关闭,在所有Pod关闭前不能调度新服务,因此引入中间状态online2offline、offline2online。
- online: 节点在线使用
- online2offline: 节点被选择出让,需要迁移残留在线实例
- offline:节点离线使用
- offline2online: 节点被选择归还,需要清理残留离线训练作业
同时这里需要单独监视Pod驱逐情况,当所有都Pod都结束后结束中间状态
我们再来看一下整体的架构图
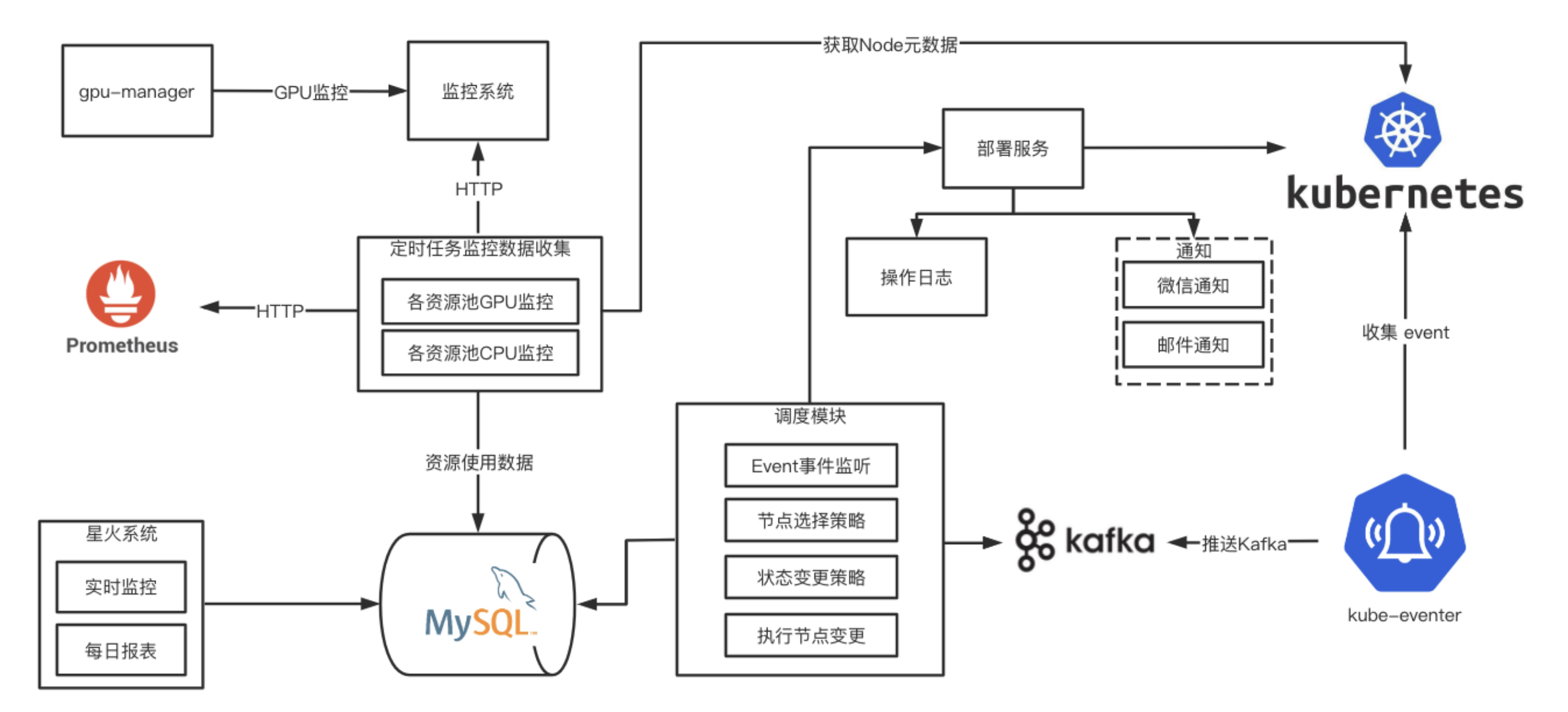
核心组件主要为调度模块、监控数据采集模块、kube-eventer模块。
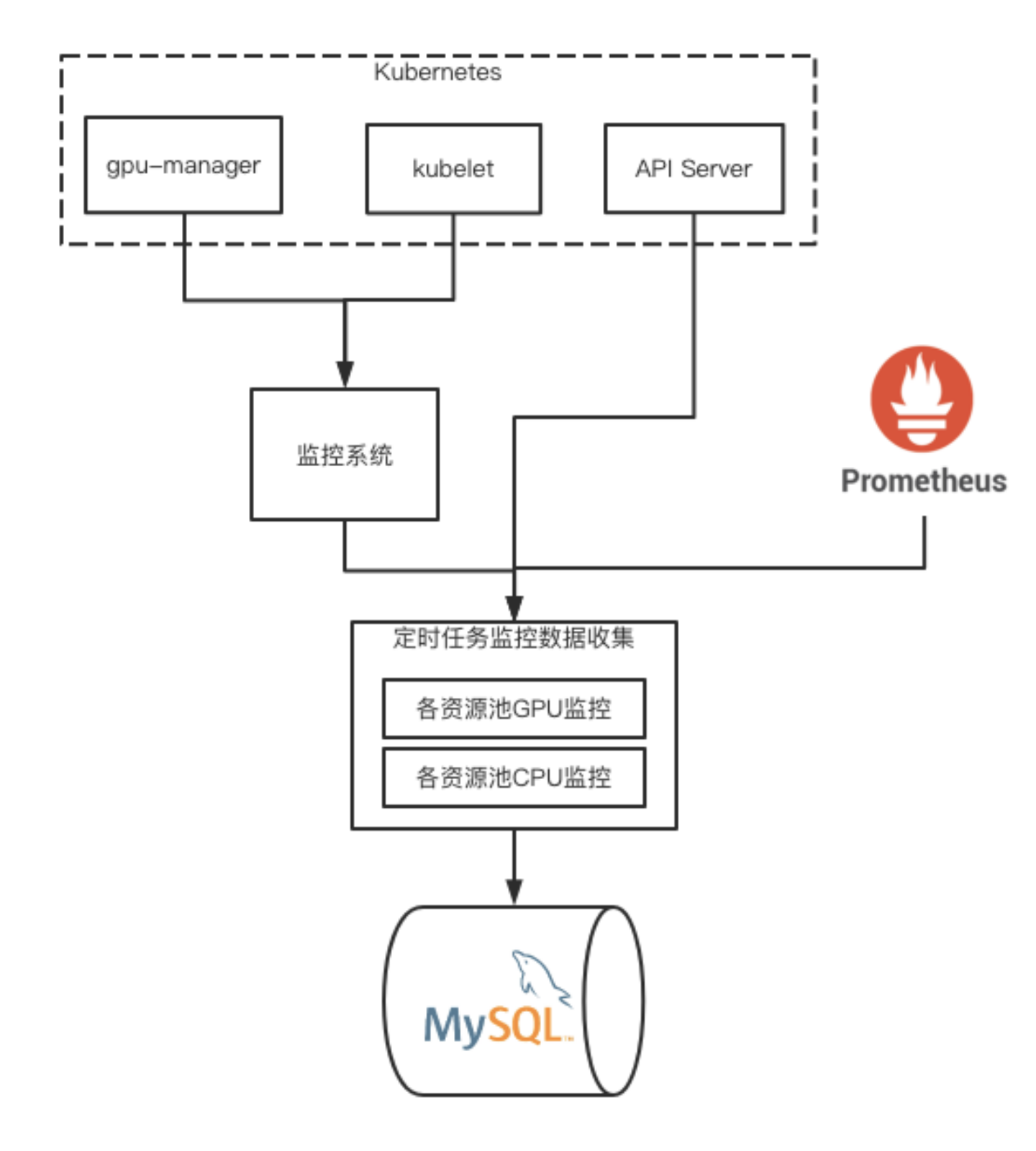
监控数据采集模块,需要从多个系统聚合出整个集群GPU/CPU资源使用率数据。
- 从K8s获取节点信息
- 从监控系统中获取不同GPU卡使用率
- 从Prometheus中获取资源Quota
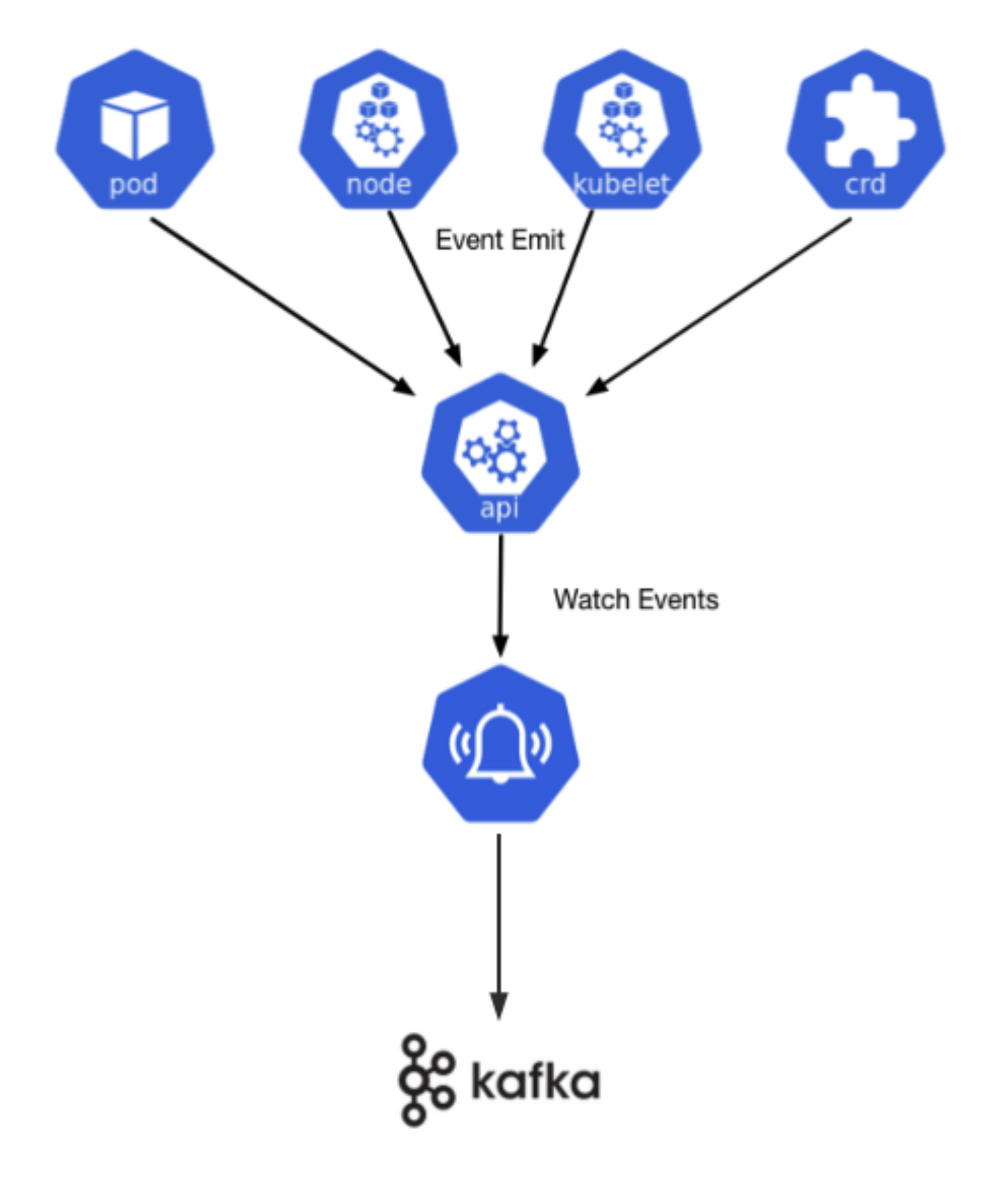
Event事件收集
通过K8s API Server监听Event事件存在如下问题:
- K8s Event事件保存etcd中,默认只保留1小时
- 消费者不能设计偏移量
- 过多消费者监听K8s会增加集群压力
因此我们通过kube-eventer统一收集Event并推送到Kafka,通过消费Kafka的形式来监听Event事件。
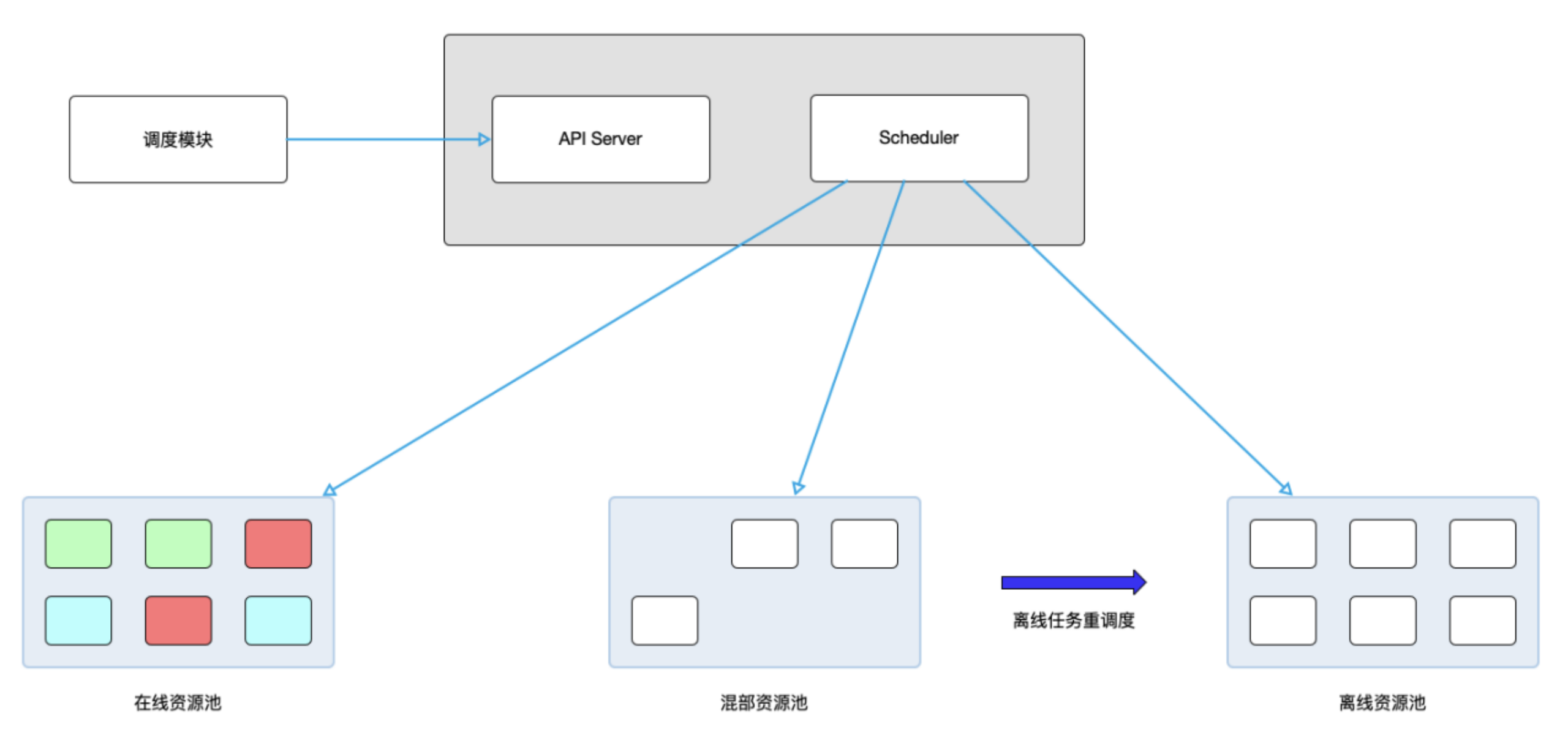
接下来再看一下节点状态变更具体流程:
online2offline
在线资源的缩容分3步,筛选节点、清理节点、离线使用
-
混部资源池中选出需要回收的节点: 先Pod数量,再GPU、CPU使用率。并保证该节点回收后,当前集群GPU/CPU使用率不高于
扩容阈值,否则停止回收。 -
将选出的节点标记为 mix-status=online2offline,并对该节点上的在线Pod进行优雅驱逐。
-
完成后标记为mix-status=offline,此时开始调度离线训练作业到该节点上。
在线资源池缩容的触发
-
因为在线推理服务每天的波动非常稳定,每天23点到次日凌晨6点触发缩容。
-
每分钟检测当前整体GPU/CPU(request)使用率,根据缩容阈值确认是否可以回收。
-
如果有因资源不足导致的Pending,停止缩容。
同时,通过监控发现,夜间会出资源使用率突然有1分钟突增,离在线混部需要对这种情况忽略,采用每选取3分钟指标,取中间值。这样,如果有1分钟内的毛刺,则会忽略。
设置上次扩容时间状态,因为服务启动需要时间,扩容完成后3分钟内除发生Pending不再执行扩容。
offline2online
在线节点归还触发如下
全天当 在线资源池CPU/GPU 使用率(request)超过 扩容阈值。
Pod自动扩容时出现Pending,根据所缺少的资源类型进行扩容。
节点归还过程如下:
-
选择混部资源池中离线训练作业数最少节点。
-
将选出的节点标记 mix-status=offline2online,并对该节点上所有任务进行重新调度。
-
完成后标记为 mix-status=online,此时开始调度在线推理任务到该节点上。
确保出让过程的平滑和稳定
减少在线推理服务驱逐,
- 扩容优先调度到在线资源池
- 缩容优先混部资源池
减少对任务训练作业影响
- 驱逐时优先选取离线训练作业最少的节点
- 离线训练作业已经驱逐的直接调度到离线集群
离线训练作业区分
将离线训练作业分为长时任务和短时任务:运行时间长、任务重跑成本高或不能重跑的为长时任务;运行时间短、可以重跑或重跑成本低的为短时任务。根据离线训练作业历史记录及任务属性区分长时、短时任务,如无法区分默认为长时任务。
短时离线训练作业设置亲和性,优先调度混部资源池,其次离线资源池。
短时离线训练作业只跑非集群任务,晚上指定时间开始调度,超过指定时间不再向混部集群中调度,晚上优先调度到混部署集群。
离线训练作业重调度
离线训练作业如果发生重调度说明在线资源开始回收,通过修改亲和性策略,优先将其调度到离线集群
总结及展望
现在已经初步证明混部效果与可靠性,未来将从下面三个方面继续推进
- 继续扩大混部资源池
- 细化调度策略,根据GPU类型进行资源分组
- 其他离线资源互通,将其他平台离线训练作业调度到混部资源池